Projection Memory, or why your agent feels like a glorified cronjob
Every agent framework has some form of memory: LangChain has three types, Mem0 raised $24M building a “memory layer,” and Letta built an entire company around persistent agent state. The result is that agents are pretty decent nowadays at remembering what happened. But for some reason we still only rely on cron for anything that happens in the future.
I’m building Bryti, a personal AI assistant, and I found this silly. I’m pretty good at remembering what happened; my problem is that I can’t seem to remember things that I need to do or properly plan for them. I don’t want to schedule reminders, I need something that understands that I need to be reminded.
So I want an AI assistant to understand that when I say “remind me later” that it will remind me later, not nag me about “when”. Or that it understands that I need to reschedule my dentist appointment if it gets canceled. And if I say something like “remind me to send an email on Monday, and also on Tuesday if I haven’t sent it yet”, that he will not remind me on Tuesday if I for some miraculous reason did do it on Monday.
I built what I’m calling projection memory. The concept is that when an agent notices I need something in the future, he will project himself into that future, plant the context he thinks he will need, and then when the future rolls around, he has the best chance to be amazing.
Investigated, implemented, benchmarked; let’s see how it turned out.
The problem with backward-looking memory
Here’s a simplified version of how most agent memory works. The user says something, the agent extracts facts and stores them, and later when the user asks something, the agent searches memory for relevant facts. The retrieval is always triggered by the user doing something; sending a message, starting a session, asking a question.
This is fine for reactive agents but it breaks for proactive ones, because if the agent needs to initiate contact (“hey, your mom’s birthday is tomorrow, you haven’t planned anything”), it needs a reason to wake up and something to say when it does.
The standard solution is timers: user says “remind me at 5pm,” agent sets a cron job, you get a message. Letta has a nice API for this; you can schedule one-time or recurring messages with timestamps or cron expressions, and the message fires at the scheduled time so the agent wakes up to handle it.
This works for explicit reminders and fails completely for everything else.
The scheduling gap
When I looked at the things I actually wanted a proactive agent to handle, the minority was explicit “remind me at X” requests. The rest were things like:
- “My ID card expires in March” mentioned while talking about a Japan trip in April (no “remind me”)
- “I need to sort out the accountant situation at some point” (no specific date at all)
- “If the client meeting gets cancelled, schedule an internal sync instead” (conditional on something else happening)
- “When the finance numbers come in, I need to start the report” (triggered by a future event, not a timestamp)
A cron-based system will never fire on these; the information exists in memory, but the system has no mechanism to connect “stored fact about the future” with “proactive action.”
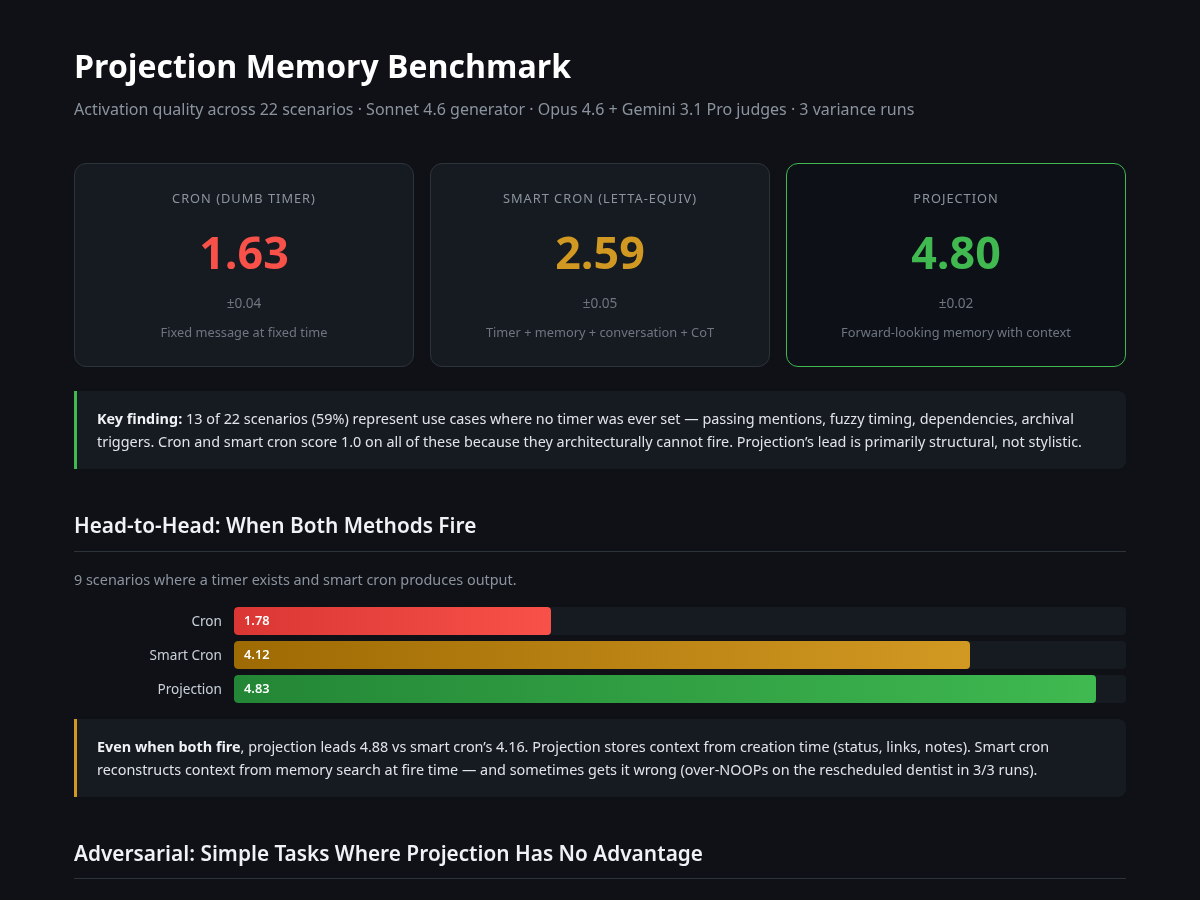
In my benchmark, 13 out of 22 test scenarios fall into this category. Not because I tried to stack the deck (though you should absolutely scrutinize that claim; I’ll get to it later), but because when you catalog the kinds of things a personal assistant should proactively handle, most of them don’t come with a timestamp attached.
What projection memory is
A projection is a forward-looking memory entry. Instead of just storing “user’s passport expires March 2026” as a fact, the system creates a structured entry:
Summary: ID card expires March 2026, needs renewal before Japan trip
Resolved when: January 2026 (month resolution)
Context: Planning Japan trip in April. Dutch renewal takes 5-10 business days.
Status: pendingDifferences from a regular memory fact:
Resolution can be exact (specific datetime), day, week, month, or “someday”. This allows the system to reason about urgency without needing a precise timestamp, which is important because most real obligations don’t have one.
Context is captured at creation time by the agent, for himself. When the agent surfaces this projection, he already knows why it matters and what background to include, rather than having to search for it at fire time. And because at creation time he had all the context, he is able to include everything he needs.
Status tracks whether this is still relevant. Cancelled events don’t fire, completed tasks get cleaned up, and this gives the agent NOOP capability; the ability to decide that silence is the correct response when an event was cancelled or a condition wasn’t met.
Dependencies and triggers connect projections to other events or facts. “When X happens, fire Y” or “only fire if Z is still pending”. Triggers can also be semantic: when a new fact enters memory that matches a projection’s condition, the projection activates, even if no timestamp was involved.
None of this is conceptually complicated. So why aren’t we all using it? Doesn’t it work?
The benchmark
I built 22 test scenarios across 10 categories and compared three methods:
Cron: timer fires, echoes the stored text. This is what you get with a basic scheduler, and many agents use only this.
Smart Cron: timer fires and the agent wakes up with full access to conversation history, memory store, and chain-of-thought reasoning. This is the best possible outcome for a Letta-style “scheduling API + archival memory” architecture. I gave it every advantage including conversation history, all relevant memory entries, and explicit NOOP instructions.
Projection: forward-looking memory entry activates with stored context, status tracking, linked projections, dependency checks, and trigger evaluation.
Sonnet 4.6 generates all responses, while Opus 4.6 and Gemini 3.1 Pro judge them. Each scenario gets scored 1-5 on usefulness, context richness, appropriateness, and coherence, and I ran the whole thing three times for variance (projection’s stddev was 0.02).
| Method | Overall (n=22) | Head-to-head (n=9) |
|---|---|---|
| Cron | 1.63 ± 0.04 | 1.80 |
| Smart Cron | 2.59 ± 0.05 | 4.16 |
| Projection | 4.80 ± 0.02 | 4.88 |
Alright so the numbers are dramatic, yet slightly misleading, without explaining the split. The overall score is much higher for projection as the crons score 1.0 on all 13 no-timer scenarios because they produce nothing; they can’t, because nothing was scheduled. The happy-path comparison is head-to-head: On the 9 scenarios where both methods fire, projection scores 4.88 versus smart cron’s 4.16.
The honest part
Before you take these numbers and run, here’s what’s wrong with them.
I wrote the scenarios. All 22 of them, and I picked the categories and decided the mix. If you reweight to 80% timer scenarios (heavily favoring smart cron), smart cron improves to 3.62 while projection barely changes at 4.82 because it scores well on both types.
On simple tasks, projection is worse. I ran 4 adversarial scenarios where projection should have no advantage: morning alarm, laundry timer, daily medication, meeting nudge. Smart cron won 4.53 to 3.88. Projection over-elaborates; it adds “tips for your meeting” and “consistency matters for medication” where a brief nudge is what the situation actually called for, and both judges penalized it for being verbose.
The retrieval is pre-computed. In the benchmark, I hand the relevant entries to all methods to control this variable. In a real system, projection has an additional advantage because it has the context stored and can search much more accurately than smart cron; but I didn’t test that, so I’m not claiming it.
LLMs judged LLMs. I did a blind human evaluation on 10 scenarios (shuffled, anonymized labels) to cross-check, and the scores were similar: projection 4.85, smart cron 3.33, cron 2.38. But it’s still only one human. A beautiful human, but still.
What I didn’t expect
The interesting finding wasn’t that projection beats smart cron. It was what happened when I made smart cron smarter.
The initial version was simple: timer fires, here’s the reminder text, here are some relevant notes, compose a message. It scored 2.74. Then I gave it the full treatment: conversation history, chain-of-thought reasoning, explicit NOOP instructions, all the memory context. The kind of setup you’d build if you were really trying to make a Letta-style architecture work well.
It scored 2.59. Lower.
On the rescheduled dentist scenario (appointment moved from 10am to 2pm, old timer fires at 9:30), beefed-up smart cron NOOPs in all three runs. It sees the conversation where the user says “moved to 2pm,” concludes the 10am reminder is irrelevant, and stays silent. Technically correct (the 10am slot is cancelled) but practically wrong (the user still needs a reminder for the new time); more context without the right data structure to organize it gave the model more rope to hang itself with.
Projection doesn’t have this problem because the projection itself was updated when the rescheduling happened. The resolved_when changed from 10:00 to 14:00, and the context field says “rescheduled from 10:00.” The model doesn’t have to reconstruct what happened from conversation history; the information is already structured correctly.
What this means for framework authors
Every framework I checked (LangChain, Mem0, Letta, and Orin Labs’ entity architecture) stores what happened, and none of them have a dedicated concept for what’s expected to happen. LangChain has three memory types (semantic, episodic, procedural), all backward-looking. Mem0 calls itself a “memory layer” but has no scheduling at all; their own reminder agent uses a separate SQLite database for the actual reminders. Letta comes closest with their scheduling API, but a scheduled message is just “send this string at this time,” and while the agent can access its memory when the message fires, the message itself carries no context, no status, no dependencies.
Orin Labs has a clever approach where agents manage their own wake schedules (the agent decides when to sleep and when to wake up), but their memory is still retrospective: temporal summaries that decay in resolution over time. They don’t have a data structure for “things that haven’t happened yet.”
The piece that’s missing is small: a forward-looking memory entry with a resolution, context, status, and some basic lifecycle management. Just a new memory primitive for this very useful piece of my brain that needs some special care and attention.
The benchmark is open
The full benchmark is on GitHub: scenarios, runner, rubric, results, and the known limitations all written down. The runner supports plugging in your own generation method, so if you’re building agent memory and want to test how your architecture handles proactive activation, it’s a reasonable starting point. You should absolutely write better scenarios than I did.
The code that implements projection memory in Bryti is about 300 lines of TypeScript, nothing fancy; just store, retrieve, format, lifecycle. The hard part isn’t the code; it’s deciding that forward-looking memory is worth being a separate concept rather than just another fact in your vector store.
