I accidentally benchmarked three free LLMs against Sonnet
I’ve started building a context engineering course for developers, with runnable exercises, code examples, the works. I’ve spent a couple hours going back and forth with a LLM to come up with the rough course content, and had said LLM commit all of our discussions to a (way too detailed) TASK.md, which I wasn’t really going to read but I am not good at throwing things away.
Now I also happened to have access to GLM-5, MiniMax M2.5 and Kimi K2.5 on a free tier, and I’ve heard good things. So why not; I pointed each of them at the task. I let them generate their own todos, and then with a loop skill in the pi agent harness let them execute them all.
I wasn’t exactly planning on evaluating them at this point, but I suddenly did have 3 directories full of data that I felt like I had to do something with (cause again, not great at throwing things away). So now I’ve spent hours on research methodologies and writing this article just so you can skim it for the numbers.
The task
The spec was 1,384 words. Deliverables:
- A course outline, 8 modules, 3-5 lessons each, 8-12 hours of content
- 8 module files, 1,500-3,000 words each, with code examples and citations to specific research papers
- 8 hands-on exercises, no paid API access required
- A reference sheet
I also included research files, from contextpatterns.com: three research summaries, ten pattern files, and two guides. The models could read them but couldn’t search the web, to reduce the confounding effect. Each model got a pi session with read, write, bash, and todo tools, plus a loop extension that re-prompts every turn with: “List open todos, pick an unclaimed one, claim it, work on it, close it. Repeat until done.”
Sessions ran 33-75 minutes per model, 92-160 turns each.
What happened
All four finished without intervention, which sounds unremarkable unless you’ve ever done anything semi-complex with loops. Given a detailed spec and a task loop, all of them planned their work, decomposed it into todos, and executed to completion without a single human prompt. Which was already a great result, honestly; I really didn’t know what to expect from these models.
Past that, the differences are significant.
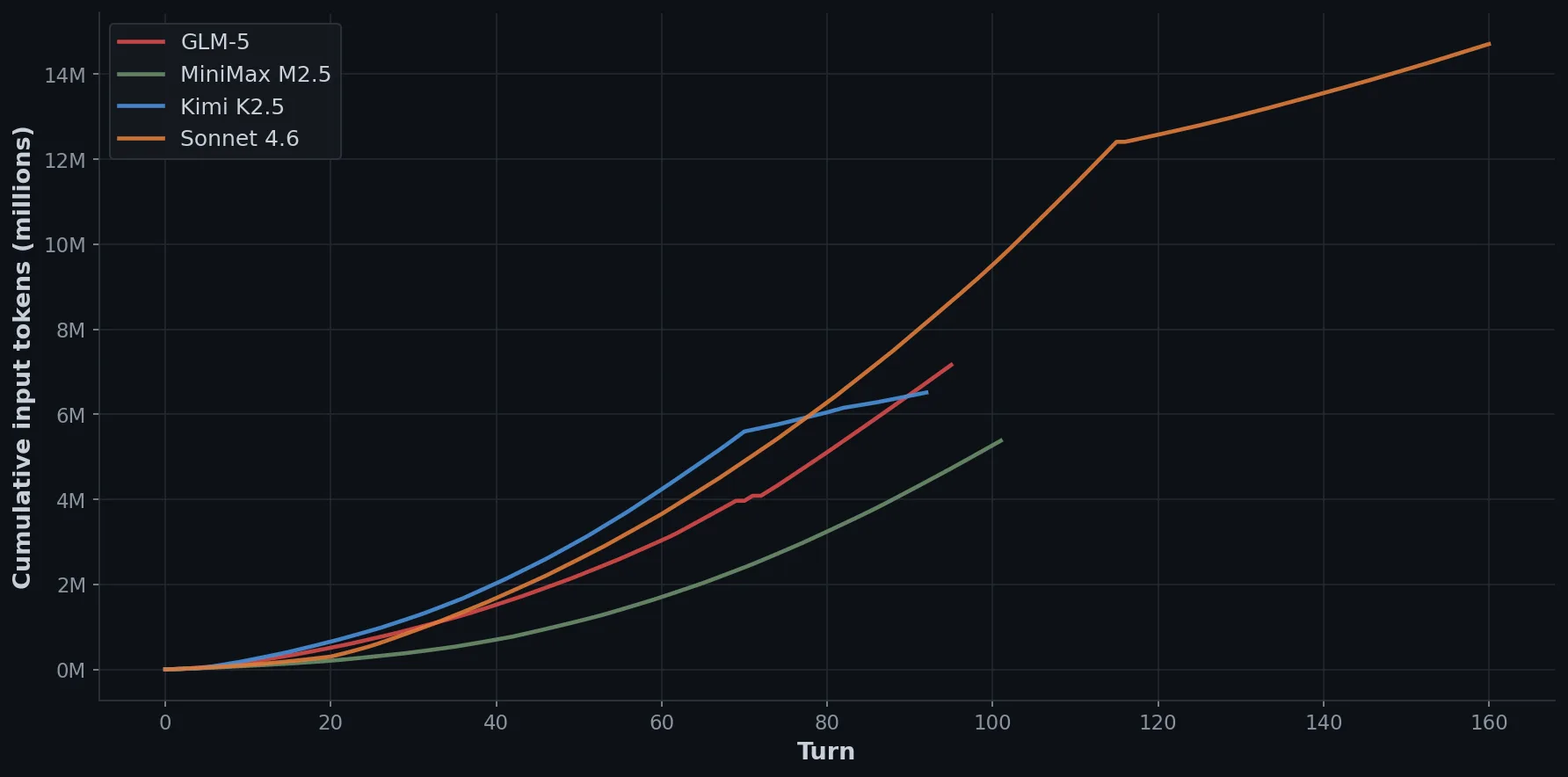
| Model | Cost | Time | Turns | Input tokens | Words | Exercises | Cache hit |
|---|---|---|---|---|---|---|---|
| MiniMax M2.5 | $0.89 | 33 min | 101 | 5.4M | 29k | 4/8 | 90% |
| Kimi K2.5 | $1.47 | 36 min | 92 | 6.5M | 41k | 8/8 | 93% |
| GLM-5 | $3.25 | 75 min | 95 | 7.2M | 39k | 8/8 | 73% |
| Sonnet 4.6 | $7.12 | 58 min | 160 | 14.7M | 51k | 8/8 | ~100% |
MiniMax finished fastest in 33 minutes. Unfortunately, it wrote a single todo for “8+ exercises”, delivered 4 and called it done. Its failure to properly decompose the task cost it valuable points. MiniMax is fast and cheap, and will interpret any ambiguity in the most minimal way possible. Fair enough.
GLM-5 wrote the most detailed planning todos of any model: structured sections for deliverables, topics, and specific data points to incorporate from the research files. Good plans, but expensive execution; it read the input research files whenever it needed a specific number, consuming 1.9 million fresh input tokens. It still hit 73% cache utilisation overall, but those 1.9M fresh tokens were billed at full input price, which adds up fast. At standard GLM pricing that’s $1.94 in fresh input alone, more than Kimi’s entire session cost.
Kimi K2.5 made an interesting judgment call: it delivered exercises as executable Python scripts with fixture files, rather than markdown with code snippets. The spec said “starter code” so this is defensible, and it’s a higher-fidelity interpretation than the other models chose. I suppose it might have been a result of the focus on coding in its training. Exercise 1 even shipped with a real session-log.jsonl fixture so it was fully self-contained.
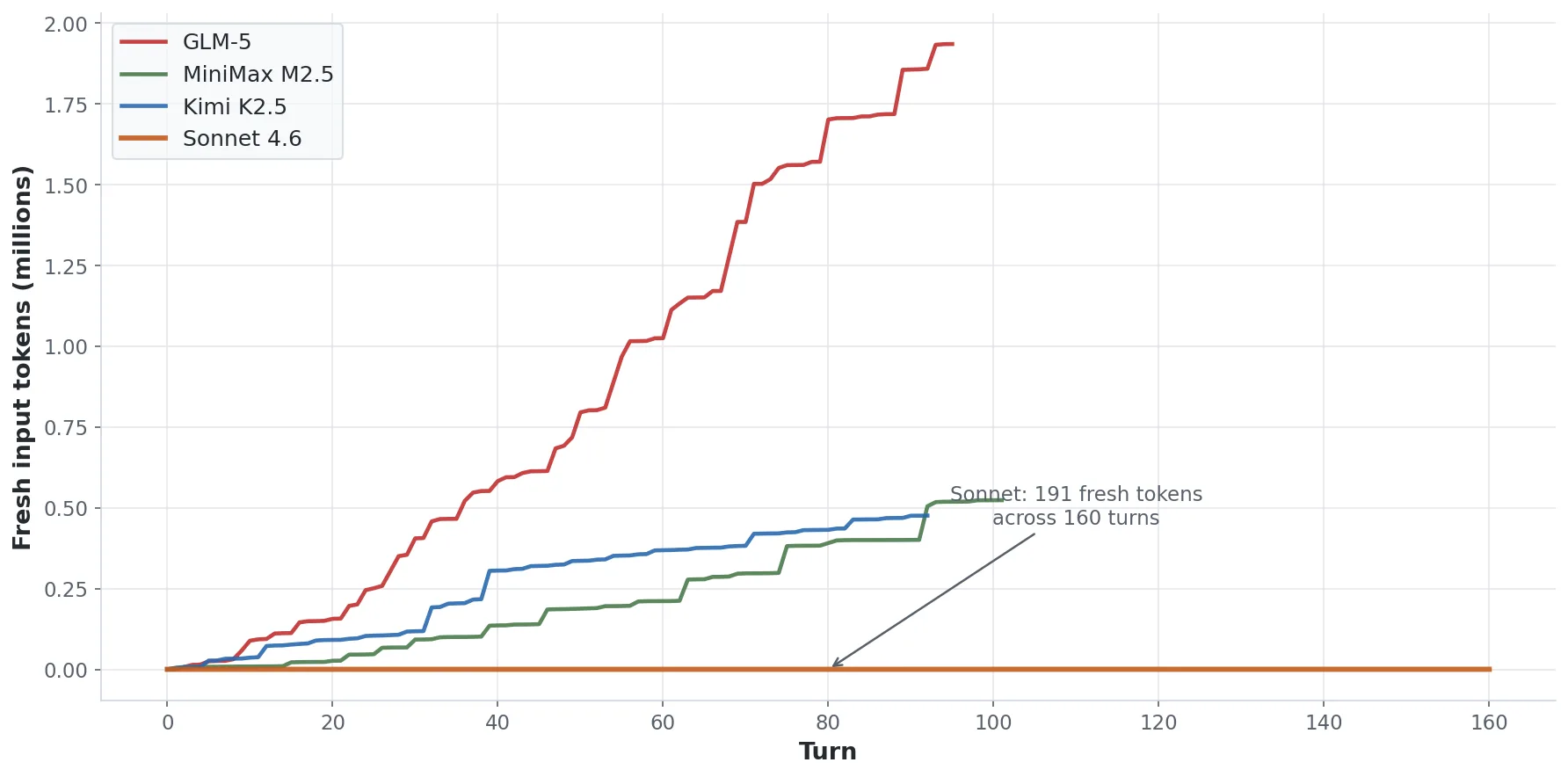
Sonnet 4.6 produced 191 fresh input tokens across 160 turns.
That number looks like a typo, so let me explain. Sonnet’s first todo was “Read all research files and source material.” It read all 15 source files in sequence, then wrote a 900-word structured reference document before producing a single line of course content. Every subsequent turn drew from the cached conversation history, which the provider serves at 10% of input price, and it never re-read a source file for the rest of the session.
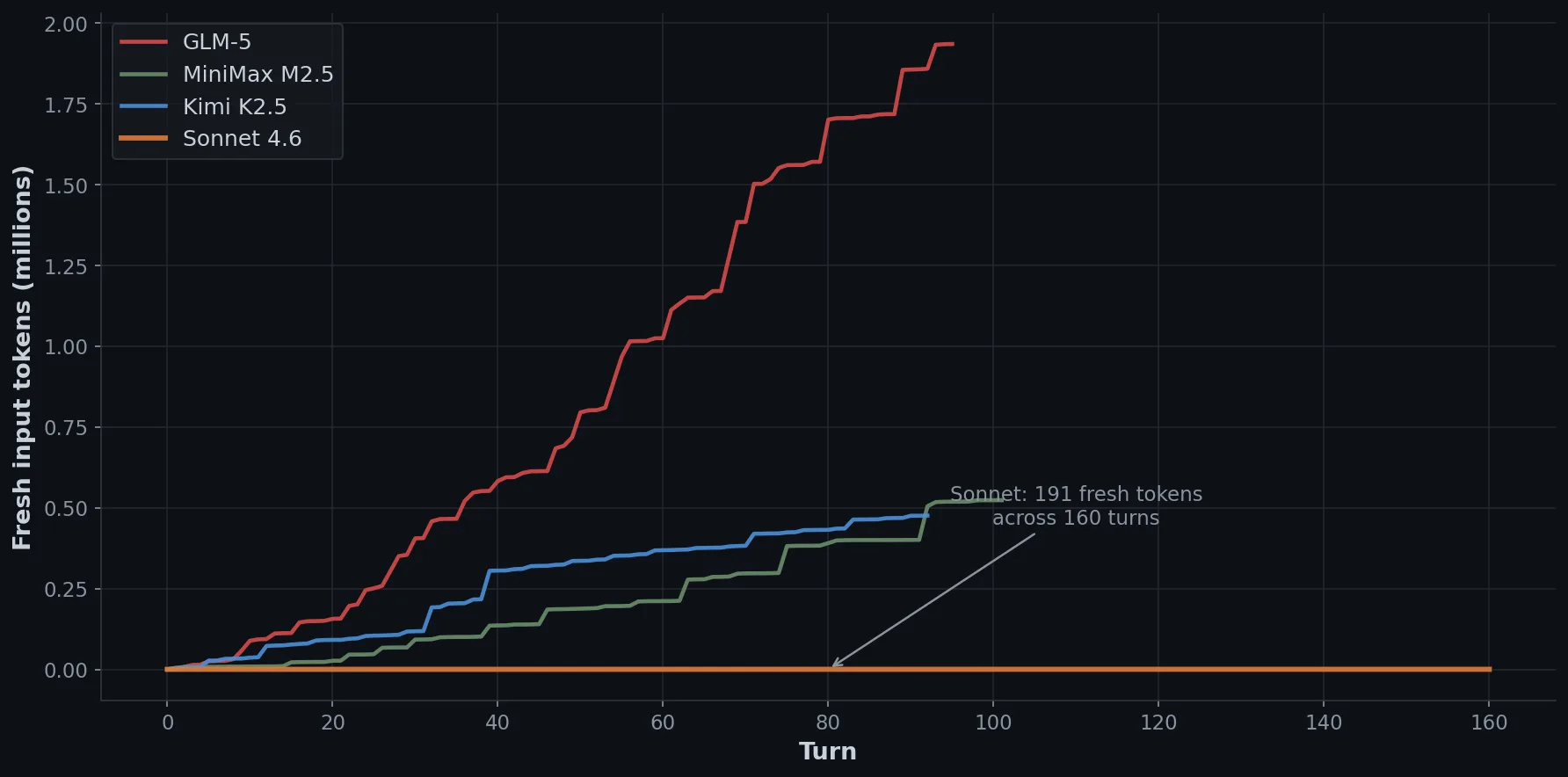
As contrast, GLM read files continuously and spent $1.94 in fresh input; Sonnet read everything once and spent effectively nothing. This isn’t a Sonnet-specific magic spell, but a context pattern any model can be prompted to follow known as Anchor turn, and the cost difference scales with session length. So in our case, pretty worthwhile.
Sonnet also added a QA pass as its last todo, which the other models skipped (amusingly, GLM-5 did plan it; participation trophy winner). After finishing all 8 modules and exercises, it ran through the spec checklist, verified word counts, spot-checked statistics against its research notes, and cleaned up style violations from the project’s coding guidelines. None of the other models read the guidelines file, let alone applied them.
But how good was the output?
Using LLMs as judges is controversial, but my opinion alone wouldn’t tell you much either. Luckily, we already established this as an informal piece of work, so freed from the suffocating shackles of academic rigor, let’s judge ahead.
I built a pairwise judge pipeline. I selected the 4 most technically demanding course modules, stripped all model names and directory paths from the content, assigned neutral labels (Alpha, Beta, Gamma, Delta), and sent every pair to two judges; Gemini 2.5 Pro and GPT 5.2. Each judge gets the same prompt: what’s the biggest weakness, are the citations real, is anything misleading, and which version would you recommend? That’s 6 pairs per module, 2 judges each, 48 evaluations total.
I went with pairwise comparison rather than rubric scoring, because models calibrate “this one is better than that one” more reliably than “this deserves a 7 out of 10”. Very human-like.
Both judges were consistent with each other, which is at least a sign the results aren’t random.
| Model | Judge record |
|---|---|
| MiniMax M2.5 | 1W / 23L |
| GLM-5 | 12W / 12L |
| Kimi K2.5 | 12W / 12L |
| Sonnet 4.6 | 23W / 1L |
Sonnet obviously takes the top spot here. The single loss was GPT-5.2 preferring GLM’s cleaner structure on the failure patterns module, penalising Sonnet for citing specific statistics it couldn’t verify. Ironic, given that the citation audit later found GLM was the one fabricating. But at a factor 2 to 9 times as expensive, Sonnet better be winning.
MiniMax lost due to its code examples. They were illustrative data structures rather than anything you’d actually run. GLM-5 and Kimi K2.5 ended up dead even at 12W/12L, with both judges from different providers (Gemini and GPT-5.2) agreeing closely. Kimi costs less than half what GLM does for the same judge quality, which makes it the better pick among the free models.
The citation problem
Hallucinations (or as the LLMs call it, “confabulations”) are one of my main worries with cheaper models. The judge evaluation also flagged fabricated citations, so I followed up with an audit.
Most key statistics are real and traceable, and the models cite them correctly. But GLM’s failure patterns module includes a 2-task accuracy figure of 35.72% that doesn’t exist in the source. The DSBC paper that was provided gives a 1-task figure and a 3-task figure, so GLM just interpolated a plausible middle value that wasn’t actually measured or mentioned.
Kimi’s version of the same module is worse: it confidently presents a full per-model accuracy table across GPT-4o, Claude, Gemini, and Llama at 4K/16K/32K/128K tokens, none of which appears in any source file.
These aren’t random hallucinations; it’s actually worse than that. They’re systematic extrapolations of real patterns in an attempt to generate data the models didn’t have. They’re numerically plausible and the surrounding context is accurate, which makes them impossible to spot without checking the source. A developer reading the module wouldn’t question them; I can’t remember ever looking up numbers in a course of all things. But exactly that is what makes this kind of fabrication more dangerous than the obviously wrong kind.
Sonnet didn’t fabricate, and I think the anchor turn is doing the real work here; by consolidating all source material into a reference document at the start, it never had a gap to fill. The free models had the same source files, but by the time they were writing module 3 it was all buried under dozens of turns of their own output. The result: they started filling in what seemed right. Which, if you want to be a bit dramatic about it, is context rot; the exact failure pattern the course they were building is supposed to teach. Now isn’t that cute.
What does this all mean?
The free models are genuinely capable. Kimi producing 41k words of substantive developer content in 36 minutes, accurately citing research, with runnable exercises, for $1.47 is not a compromise you need to apologise for. For content generation tasks where you’ll do an editorial pass anyway, that’s entirely reasonable.
The gap to Sonnet is real but shows up in planning behaviour rather than raw output quality. Sonnet invented the research-consolidation step and the QA pass unprompted; the free models didn’t. Those two decisions explain most of the quality difference, through better source anchoring, self-verification, and lower fabrication risk. You can probably replicate a lot of that through proper prompting. Which does make an equally proper case for an expensive supervisor model planning for a lot of cheaper workers.
GLM’s token consumption pattern is the clearest illustration of why agentic strategy matters independently of model capability. Reading research files on demand throughout a session sounds like it should produce better results because the model has the material fresh when it needs it, but it doesn’t, and it costs twice as much as reading everything once at the start. The model you pick is one variable; how the agent uses the context window is another.
On the citation issue, I’d actually separate it from the quality ranking entirely. Sonnet scored best and had the cleanest citations, but that correlation isn’t guaranteed to hold across different tasks. The fabrication behaviour is a property of how all these models handle gaps in their context, not just the weaker ones. Any content pipeline that relies on model-generated statistics needs a verification step regardless of which model you use, and that step should focus on numerical claims specifically, since those are where the precise-but-invented figures show up.
Obviously, this isn’t a benchmark. We did one run for each model for a single task, and we used free tier endpoints that may differ from production. This is just a reasonably honest look at how these models behave under real working conditions, with real data (or at least a real purpose), for a task that isn’t just “summarise this” or “code that”.
I’ve since then worked with each of the models individually, and actually the rough shape of the comparison feels right to me. Kimi is a capable coder, GLM-5 feels like an academic, and MiniMax like that guy in the back of class who always manages to find a way to a passing grade. I’m genuinely rooting for them to give the big three a run for their money.
The course is on context engineering, which is the discipline of managing what goes into an LLM’s context window. If you’re interested in hearing about this course when it ships, you can follow along here.
